


MySQL中的redo log和undo log日志详解
MySQL日志系统中最重要的日志为重做日志redo log和归档日志bin log,后者为MySQL Server层的日志,前者为InnoDB存储引擎层的日志。
1 重做日志redo log
1.1 什么是redo log
redo log用于保证事务的持久性,即ACID中的D。
持久性:指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。
redo log有两种类型,分别为物理重做日志和逻辑重做日志。在InnoDB中redo log大多数情况下是一个物理日志,记录数据页面的物理变化(实际的数据值)。
1.2 redo log的功能
redo log的主要功能是用于数据库崩溃时的数据恢复。
1.3 redo log的组成
redo log可以分为以下两部分
存储在内存中的重做日志缓冲区存储在磁盘上的重做日志文件
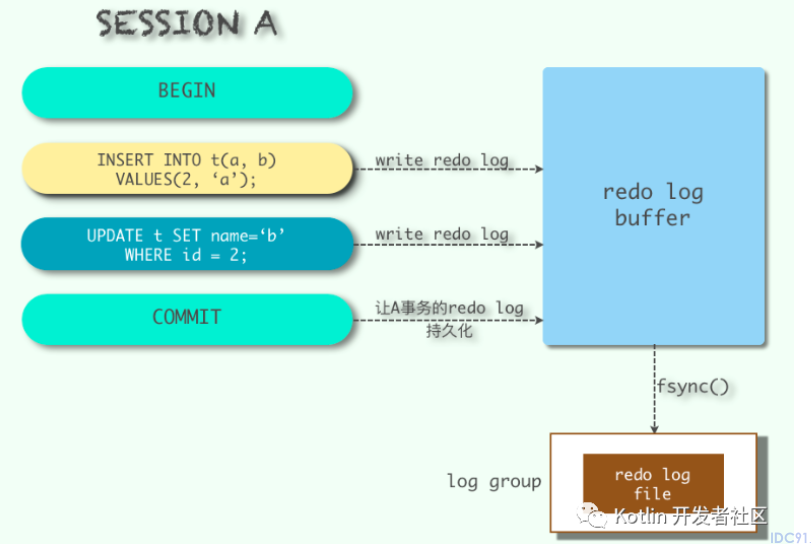
1.4 记录redo log的时机
在完成数据的修改之后,脏页刷入磁盘之前写入重做日志缓冲区。即先修改,再写入。
脏页:内存中与磁盘上不一致的数据(并不是坏的!)
在以下情况下,redo log由重做日志缓冲区写入磁盘上的重做日志文件。
- redo log buffer的日志占据redo log buffer总容量的一半时,将redo log写入磁盘。
- 一个事务提交时,他的redo log都刷入磁盘,这样可以保证数据绝不丢失(最常见的情况)。注意这时内存中的脏页可能尚未全部写入磁盘。
- 后台线程定时刷新,有一个后台线程每过一秒就将redo log写入磁盘。
- MySQL关闭时,redo log都被写入磁盘。
第一种情况和第四种情况一定会执行redo log的写入,第二种情况和第三种情况的执行要根据参数innodb_flush_log_at_trx_commit的设定值,在下文会有详细描述。
索引的创建也需要记录redo log。
1.5 一个重做全过程的示例
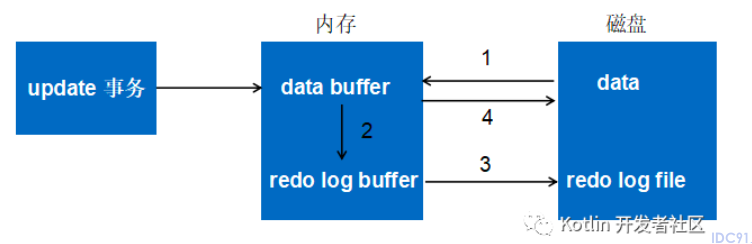
以更新事务为例。
- 将原始数据读入内存,修改数据的内存副本。
- 生成redo log并写入重做日志缓冲区,redo log中存储的是修改后的新值。
- 事务提交时,将重做日志缓冲区中的内容刷新到重做日志文件。
- 随后正常将内存中的脏页刷回磁盘。
1.6 持久性的保证
1.6.1 Force Log at Commit机制
Force Log at Commit机制实现了事务的持久性。在内存中操作时,日志被写入重做日志缓冲区。但在事务提交之前,必须首先将所有日志写入磁盘上的重做日志文件。
为了确保每个日志都写入重做日志文件,必须使用一个fsync系统调用,确保OS buffer中的日志被完整地写入磁盘上的log file。
fsync系统调用:需要你在入参的位置上传递给他一个fd,然后系统调用就会对这个fd指向的文件起作用。fsync会确保一直到写磁盘操作结束才会返回,所以当你的程序使用这个函数并且它成功返回时,就说明数据肯定已经安全的落盘了。所以fsync适合数据库这种程序。
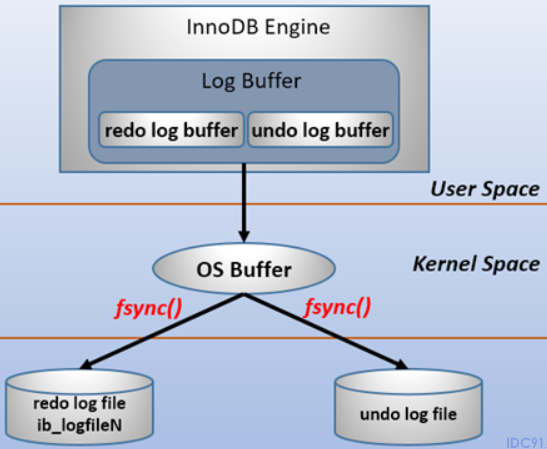
1.6.2 innodb_flush_log_at_trx_commit参数
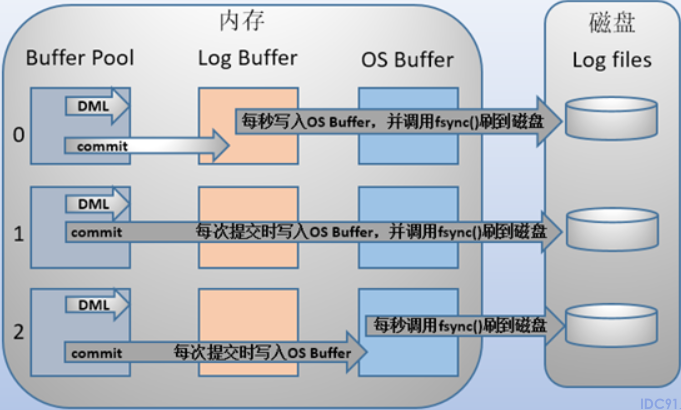
InnoDB提供了一个参数innodb_flush_log_at_trx_commit控制日志刷新到磁盘的策略。
- 当
innodb_flush_log_at_trx_commit值为1时(默认)。事务每次提交都必须将log buffer中的日志写入os buffer并调用fsync()写入磁盘中。
这种方式即使系统崩溃也不会丢失任何数据,但是因为每次提交都写入磁盘,IO性能较差。
- 当
innodb_flush_log_at_trx_commit值为0时。事务提交时不将log buffer写入到os buffer,而是每秒写入os buffer并调用fsync()写入到log file on disk中。
这实际上相当于在内存中维护了一个用户设计的缓冲区,它减少了和os buffer之间的数据传输,有更好的性能。
每秒写入磁盘,系统崩溃会丢失1s的数据。
- 当
innodb_flush_log_at_trx_commit值为2时。每次提交都仅写入os buffer,然后每秒调用fsync()将os buffer中的日志写入到log file on disk中。
虽然说我们是每秒调用fsync()将os buffer中的日志写入到log file on disk中,但是平时即使不调用fsync,数据也会2自主地逐渐进入磁盘。所以当发生系统崩溃,相比第二种情况,会丢失较少的数据。
但同时,由于每次提交都写入os buffer,所以相比第二种情况,性能会差一些,但还是比第一种好的。
无论是哪种情况
1.6.3 一个小的性能测试
几个选项之间的性能差距是极大的,下面做一个简单的测试。
#创建测试表
drop table if exists test_flush_log;
create table test_flush_log(id int,name char(50))engine=innodb;
#创建插入指定行数的记录到测试表中的存储过程
drop procedure if exists proc;
delimiter $$
create procedure proc(i int)
begin
declare s int default 1;
declare c char(50) default repeat('a',50);
while s<=i do
start transaction;
insert into test_flush_log values(null,c);
commit;
set s=s+1;
end while;
end$$
delimiter ;
栏 目:MySQL
下一篇:为什么MySQL选择Repeatable Read作为默认隔离级别
本文标题:MySQL中的redo log和undo log日志详解
本文地址:https://idc91.com/shujuku/3480.html
您可能感兴趣的文章
- 05-31MySQL中的 inner join 和 left join的区别解析(小结果集驱动大结果集)
- 05-31MySQL索引失效十种场景与优化方案
- 05-31MYSQL 高级文本查询之regexp_like和REGEXP详解
- 05-31MySQL获取binlog的开始时间和结束时间(最新方法)
- 05-31MySQL索引查询的具体使用
- 05-31基于MySQL和Redis扣减库存的实践
- 05-31关于MySQL的存储过程与存储函数
- 05-31MySQL实战文章(非常全的基础入门类教程)
- 05-31MySQL Flink Watermark实现事件时间处理的关键技术
- 05-31MySQL Flink实时流处理的核心技术之窗口机制


阅读排行
推荐教程
- 05-30开启MySQL远程连接的方法
- 05-30MySQL数据库中varchar类型的数字比较大小的方法
- 05-30浅谈mysql返回Boolean类型的几种情况
- 05-30MySQL线上死锁分析实战
- 05-30Prometheus 监控MySQL使用grafana展示
- 05-30CentOS7安装MySQL 8.0.26的过程
- 05-30Navicat for MySQL 11注册码激活码汇总
- 05-30详解mysql触发器trigger实例
- 05-30MySQL高可用架构之MHA架构全解
- 05-30mysql 8.0.24 安装配置方法图文教程