


一看就懂的MySQL的聚簇索引及聚簇索引是如何长高的
这一篇笔记我们简述一下
- MySQL的B+Tree索引到底是咋回事?
- 聚簇索引索引到底是如何长高的。
一点一点看,其实蛮好理解的。
如果你看过了我之前的笔记,你肯定知道了MySQL进行CRUD是在内存中进行的,也就是在Buffer Pool中。然后你也知道了当内存中没有MySQL需要的数据时,MySQL会从Disk中通过IO操作将数据读入内存中。读取的单位呢就是:数据页
一般数据页长下面这样
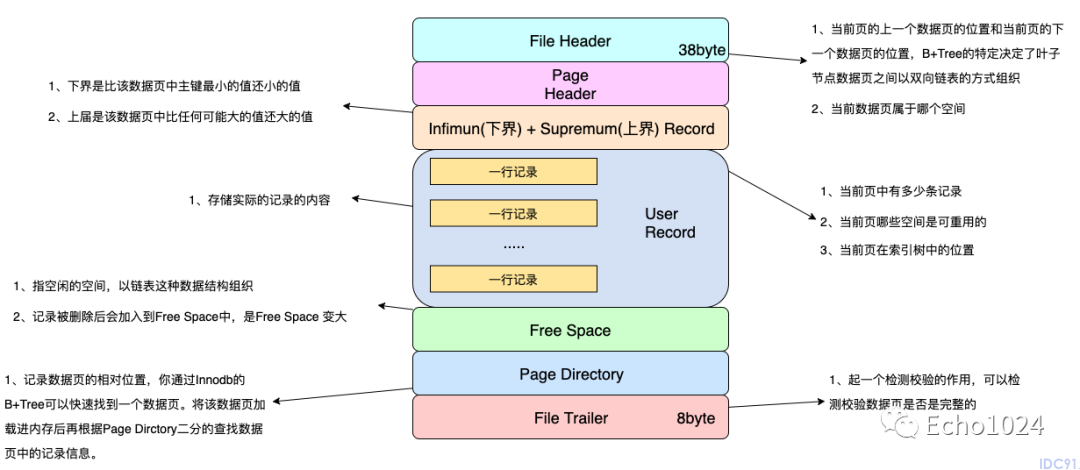
没错,数据页中存储着真实的数据,而且数据页在内存中是以双向联表的方式组织起来的!如下图
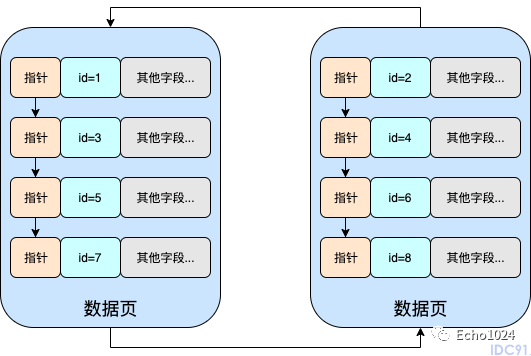
而在B+Tree的设定中,它要求主键索引时递增的,也就是说如果主键索引时递增的话,那么就要求右侧的数据页中的所有数据均比左侧数据页中的数据大。但是很明显上图并不符合,因此需要通过页分裂来调整成下面这样。

好,现在你回想一下,之前你肯定有听说过:MySQL的B+Tree聚簇索引,只有叶子节点才存储真实的数据,而非叶子节点中存储的是索引数据,而且叶子节点之间是通过双向链表连接起来
没错,那所有的B+Tree的叶子节点就是上图中的数据页,并且它们确实是通过双向链表关联起来的!
我们接着往下看,如果只看上图由数据页连接起来的双向链表的话,这时如果我们检索id=7的数据行,那会发生什么?
很明显我们要从头开始扫描!
那你可能会问:方才不是说B+Tree要求主键是递增的嘛?并且有页分裂机制保证右边的数据页中的所有数据均比它左边的数据页的索引值大。那进行二分查找不行嘛?
答:是的,确实可以在单个数据页中进行二分查找,但是数据页之间的组织关系是链表呀,所以从头开始遍历是避免不了的。
那MySQL怎么办的呢?
如下图:MySQL针对诸多的数据页抽象出了一个索引目录
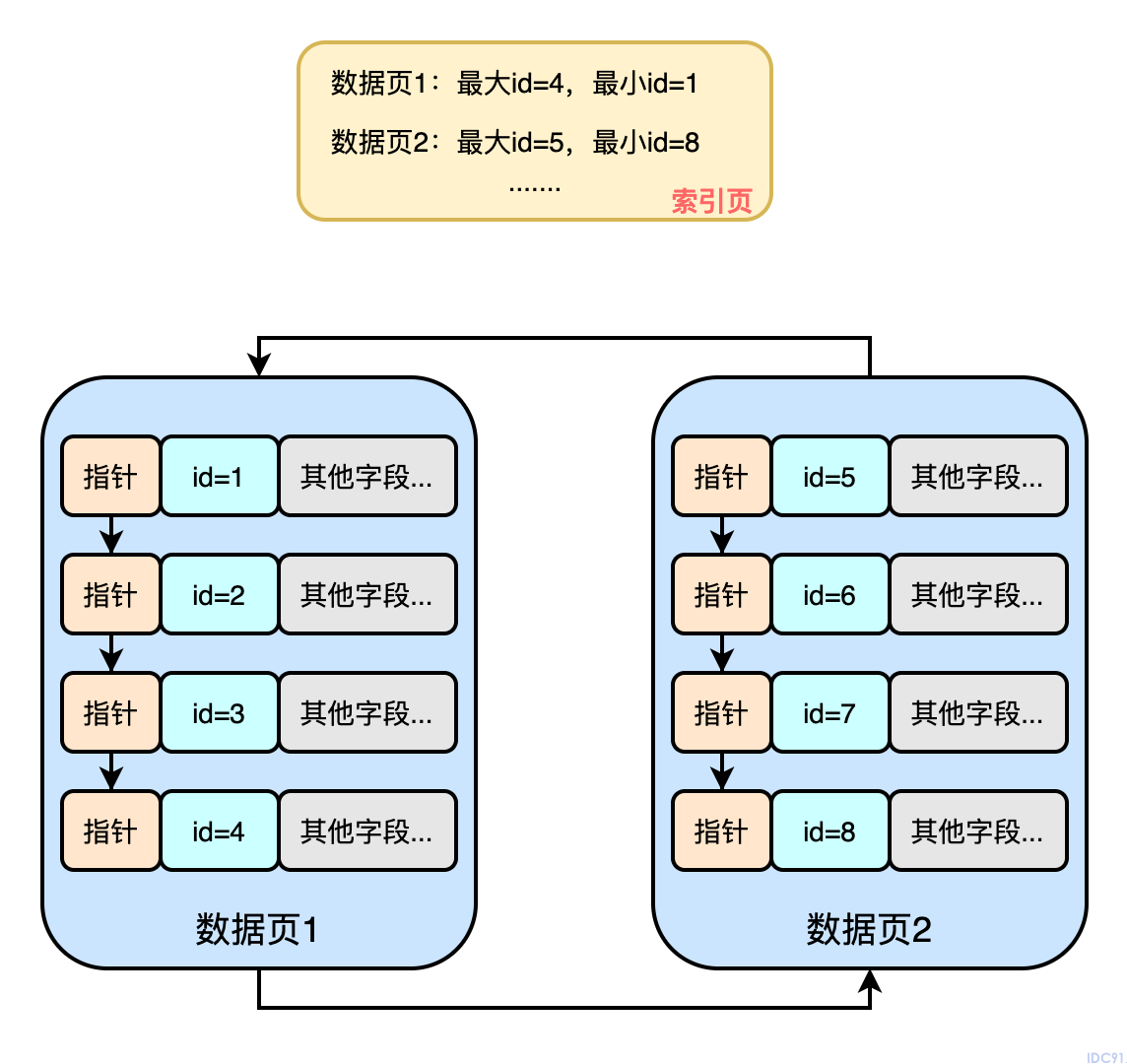
那有了这个索引目录我们再在诸多的数据页中检索时看起来就容易多了!直接就拥有了二分检索的能力!
而且这个所以目录其实也是存在于数据页中的,不同于叶子节点的是,它里面知识存储了索引信息,而叶子节点中存储的是真实数据?
而索引页的诞生也就意味着B+Tree的雏形已经诞生了!
随着用户不断的select,buffer pool中的数据页的越来越多,那么索引页中的数据也会水涨船高。当现有的索引体量超过16KB(一个数据页的容量)时就不得不搞一个新的索引页来存储新的索引信息。这时这颗B+Tree就会慢慢变得越来越胖。
那你也知道B+Tree是B树的变种,而B树其实可以是2-3树、2-3-4数....等等M阶树的泛称,当每个节点中能存储的元素达到上限后,树就会长高(上一篇文章有讲过)。
就像下图这样:

以上就是一看就懂的MySQL的聚簇索引及聚簇索引是如何长高的的详细内容,更多关于MySQL聚簇索引的资料请关注脚本之家其它相关文章!
您可能感兴趣的文章:- MySQL学习教程之聚簇索引
- 详解MySQL 聚簇索引与非聚簇索引
- mysql聚簇索引的页分裂原理实例分析
上一篇:跳槽必备之你设计索引的原则是什么?怎么避免索引失效?
栏 目:MySQL
本文标题:一看就懂的MySQL的聚簇索引及聚簇索引是如何长高的
本文地址:https://idc91.com/shujuku/3645.html
您可能感兴趣的文章
- 05-31MySQL中的 inner join 和 left join的区别解析(小结果集驱动大结果集)
- 05-31MySQL索引失效十种场景与优化方案
- 05-31MYSQL 高级文本查询之regexp_like和REGEXP详解
- 05-31MySQL获取binlog的开始时间和结束时间(最新方法)
- 05-31MySQL索引查询的具体使用
- 05-31基于MySQL和Redis扣减库存的实践
- 05-31关于MySQL的存储过程与存储函数
- 05-31MySQL实战文章(非常全的基础入门类教程)
- 05-31MySQL Flink Watermark实现事件时间处理的关键技术
- 05-31MySQL Flink实时流处理的核心技术之窗口机制


阅读排行
推荐教程
- 05-30开启MySQL远程连接的方法
- 05-30MySQL数据库中varchar类型的数字比较大小的方法
- 05-30浅谈mysql返回Boolean类型的几种情况
- 05-30MySQL线上死锁分析实战
- 05-30Prometheus 监控MySQL使用grafana展示
- 05-30CentOS7安装MySQL 8.0.26的过程
- 05-30Navicat for MySQL 11注册码激活码汇总
- 05-30详解mysql触发器trigger实例
- 05-30MySQL高可用架构之MHA架构全解
- 05-30mysql 8.0.24 安装配置方法图文教程